

Trustrorthy AI
Knowledge Base
Data Distribution
This is amongst the lengthiest discussions of any single dimension in this white paper, owing to the centrality of data to any AI strategy.
Data Distribution provides for data consolidation in (for example) OneLake, and for all manner of “downstream” data distribution such as search, APIs, data warehousing, analytical workloads, data science and data engineering workloads, and use of data in AI-driven scenarios. We also place Microsoft 365 Copilot in the Data Distribution neighborhood as it - like many other scenario-specific Copilots that also reside there - relies on consuming, interpreting, and otherwise distributing data in response to user prompts. Note that M365 Copilot is hydrated with data from Microsoft 365 via the Microsoft Graph and may be configured to consume data from elsewhere in the data estate, as well.
Pre-requisite to your use of AI is consolidation of data in storage services where it can be aggregated and accessed by AI services. Data is the essential fuel without which AI models cannot be trained nor have the capacity to act on the information that makes them valuable. For all the advancements in cloud technology of the last decade, most organizations are home to vast unconsolidated stores of data. Your data lives in OneDrive, spreadsheets, desktops and one-off databases often sitting beneath point solutions, and - if you’re lucky - some of it lives in lakes, warehouses, lake houses, and properly managed databases.
¹The technologies listed here are Microsoft-specific, so note that organizations with a more technical landscape may be using alternatives to the services listed.
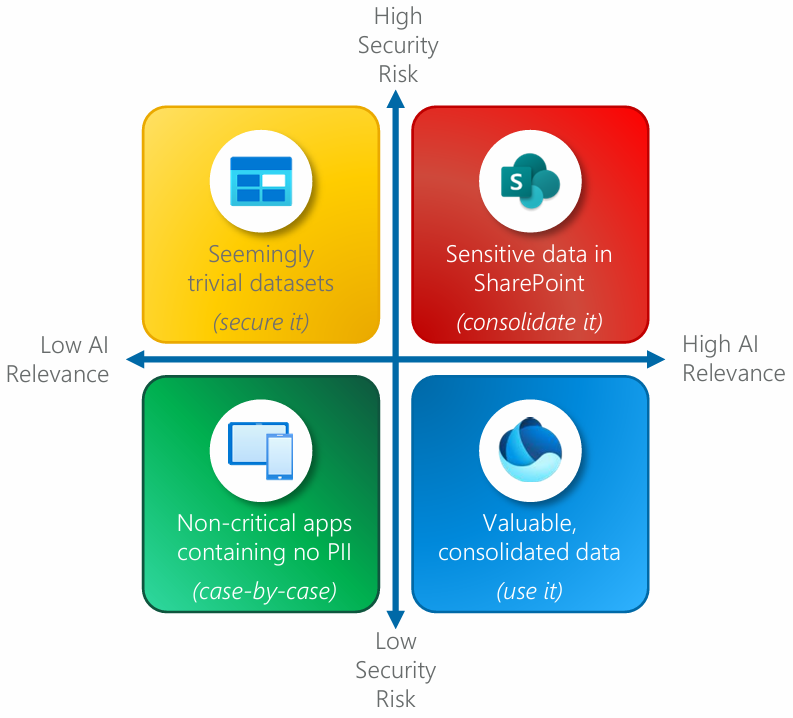
Figure 11: Consider this model when mapping out your data consolidation approach. Remember that not all data needs to be consolidated, for example, in the case of “seemingly trivial datasets” that need to be secured, but if not being used in AI or other distributive workloads, may not need to be consolidated.
This disarray results from the convergence of a lack of capability and a lack of will. Microsoft Fabric, announced in May 2023 , represents a significant investment and resulting leap forward in the capability side of the equation. Microsoft’s Corporate VP of Azure Data, Arun Ulagaratchagan, heralded Fabric as “empowering data and business professionals alike to unlock the potential of their data and lay the foundation for the era of AI.” Though Fabric offers capabilities beyond data consolidation, a significant share of its value comes from its capabilities to move and store consolidated data. OneLake, built atop Azure Data Lake Storage (ADLS) Gen2, provides one single lake for the entire organization (with a 1:1 relationship between OneLake and the tenant) and one copy of data for use in multiple data distribution scenarios including AI and beyond, such as in enterprise search, distribution via (say) API, and analytical workloads in Power BI.
Data consolidation refers specifically to the consolidation of data from across your cloud estate into storage technologies that can be accessed and used by AI. This is likely to be achieved through a variety of techniques including: copying, one-time migration with the intent to retire the legacy data source, data integration (which is, implicitly, ongoing), standardization on one or a small number of future-ready transactional data services for app dev, and employing “shortcuts” in Fabric through which data is shortcut from its source into OneLake (analogous to how a file in OneDrive may be shortcut from its source to another location).
To be clear: We are not suggesting that all data needs to be copied to a single location, nor are we advocating for the use of a single data storage technology within any one organization (which is, frankly, a preposterous idea). We’ll spare you a deep dive into each of the consolidation techniques mentioned above and say simply that ecosystem, enterprise, and solution architects possess a variety of context-appropriate data consolidation techniques that may be employed to get from your current state of disarray into a consolidated, future-ready state.
Think of data consolidation not as a single, fixed end state but rather the existence of your enterprise data estate along a spectrum. At one end we have a wholly unconsolidated stat - — the technical term for this ought to be “epic mess” - and at the other end we have a truly single source of truth for data.
Though that “truly single source of truth for data” sounds romantic, and is a fantastic aspiration, it’s also not likely to be achieved by most organizations in anything resembling the short term.
Each organization’s happy medium is likely to fall somewhere on this spectrum.
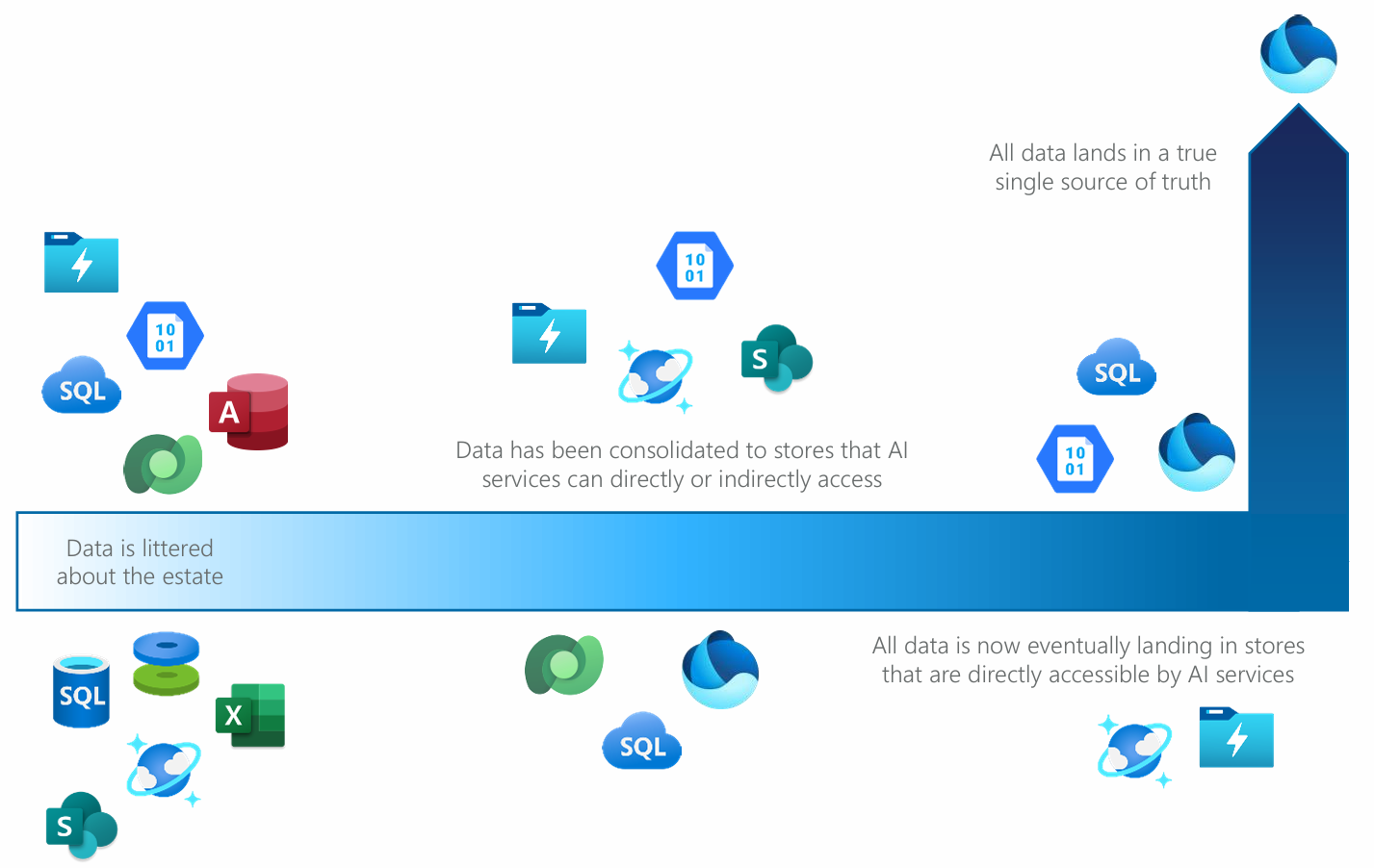
Figure 12: Data consolidation occurs on a spectrum. Do not imagine that a truly single data store is the goal.
We also need to distinguish between application data vs. data stored and staged for downstream distribution (including for use in AI workloads). For example, Dataverse (the green vortex icon in the previous diagram) is an excellent data service atop which to build applications, though it is more efficient to consolidate data from Dataverse into the lake when staging it for downstream distribution. This is the expected pattern in Microsoft business applications—be it custom solutions built with Power Platform or Microsoft’s pre-built Dynamics solutions—where data is pushed via copy or shortcut from Dataverse (the applications’ transactional data service) into the lake for downstream distribution.
Most importantly, regardless of the upstream data services you’re employing, the data that you wish to be addressable by downstream workloads, be they AI, enterprise search, analytical (Power BI), etc., must ultimately land in storage services that can feed a multitude of downstream distribution scenarios (including, but not limited to, AI).
So, returning to our earlier model, most organizations are likely to land on a data consolidation architecture that looks something like the diagram shown below. Here we see data migrated (dotted line) out of, for example, Access databases and Excel files into Dataverse, on-premise SQL into Azure SQL, or network storage into Azure Blob. You’ll then find yourself with a fairly sizable transactional data estate underpinning most of your applications whose data flows downstream to services such as OneLake. For example, data from Azure SQL is pushed or shortcut into the lake.
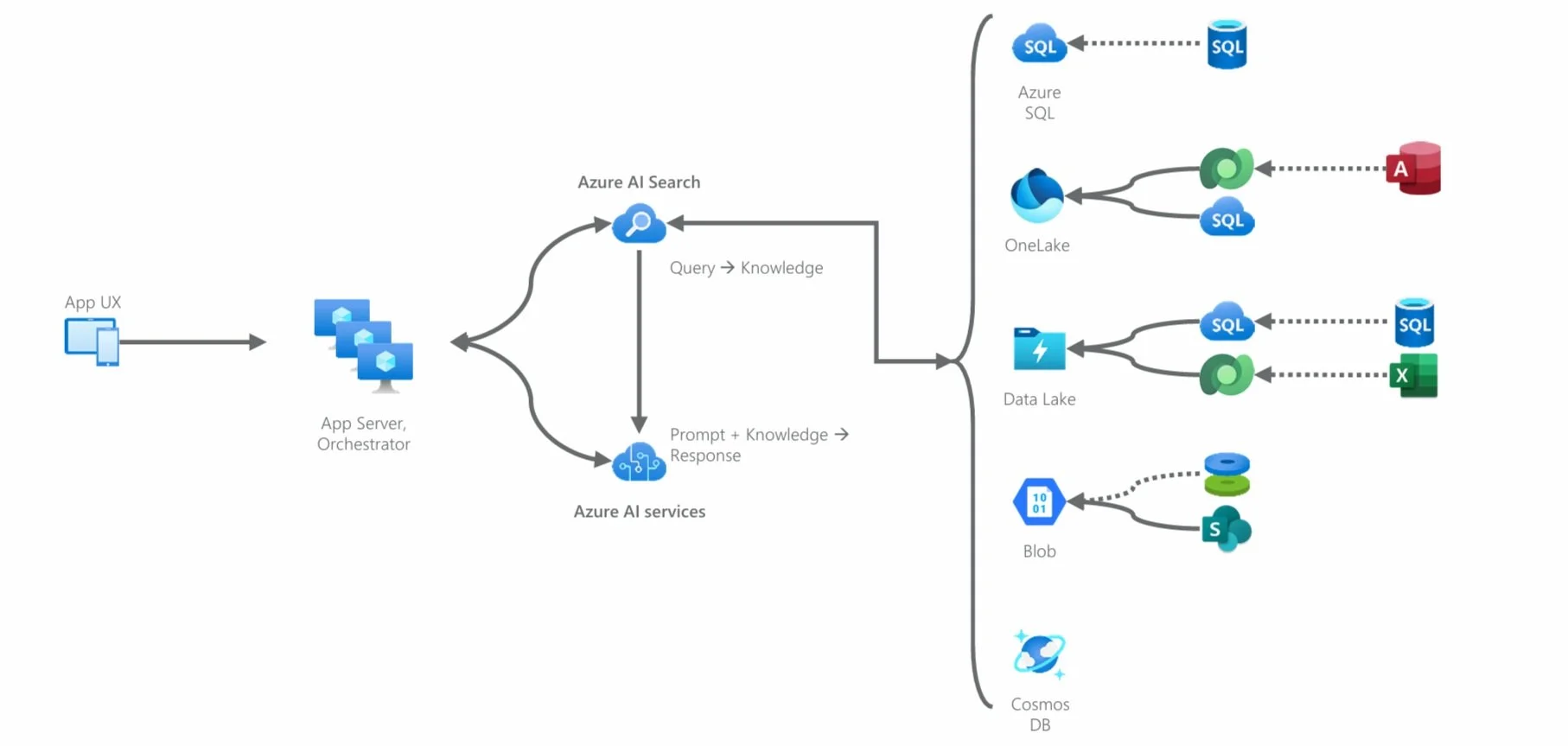
Figure 13: A notional architecture for data consolidation in practice working with the AI model we discussed earlier.
Think of these migration and integration paths as the rivers and tributaries by which data flows to the lake and other related, consolidated services. It’s rather basic data platform 101 stuff. Given how incomplete this architecture is in most organizations - and how essential it is given that it lays the foundation for your AI strategy - it really does bear including here.
Though we possess increasingly sophisticated technical capabilities to make data consolidation a reality, successfully executing on this pillar of your AI strategy requires the organizational will to do so. Grassroots action within a typical organization is insufficient and likely to result in further, randomized diffusion of data across the estate. So too is point-solution oriented architecture, which tends to neglect data consolidation in favor of data storage for application specific data services.
Data consolidation is, for this reason, one of the most important executive-led priorities in technology today as IT organizations the world over race to build future-ready ecosystems.
Let’s now turn our attention towards what should happen with the data once it has been consolidated.
The architecture below shows a fairly typical “data distribution neighborhood”, largely as shown in the reference ecosystem. We’ve simplified it by showing some undefined number of unstructured and structured data sources being consolidated into the neighborhood.
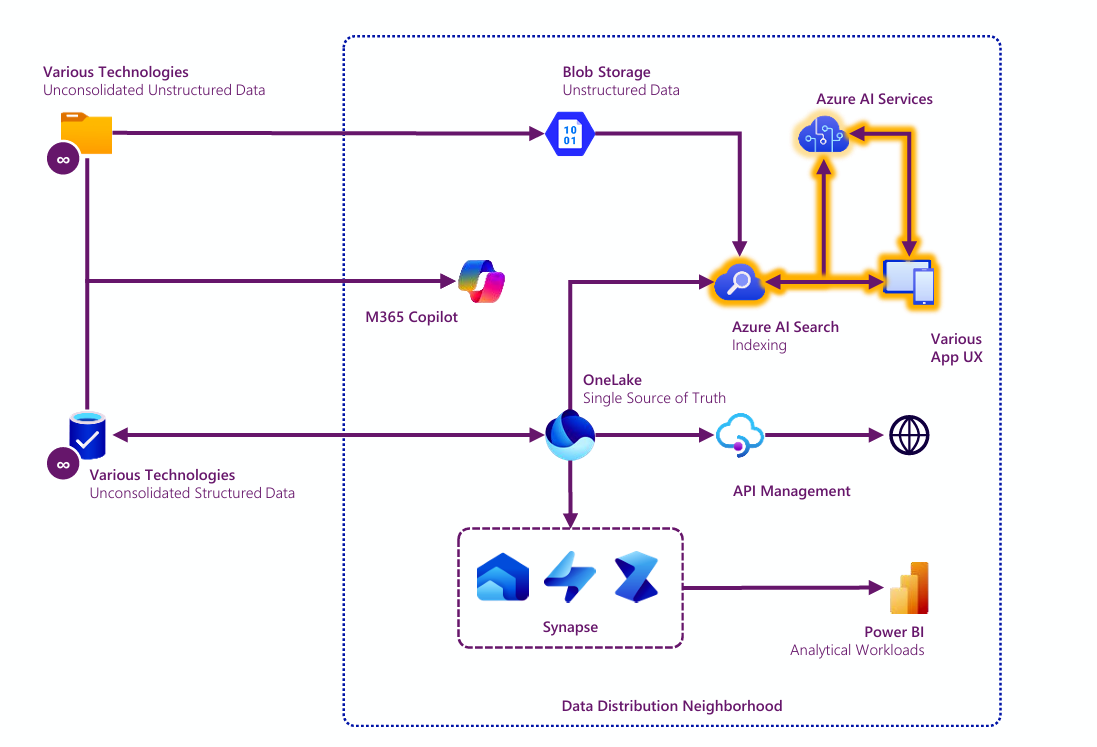
Figure 14: Notional data distribution “neighborhood” with Azure AI Search (glowing yellow) called out as the linchpin for indexing data for use in AI workloads. Other examples of data distribution are shown illustratively
There are several key components to note below:
• We’re representatively showing most structured data consolidated to OneLake and most unstructured data consolidated to Blob Storage. We could have made other technology choices here (though OneLake is pretty undisputable, in our opinion), but have chosen representative examples;Data consolidation is, for this reason, one of the most important executive-led priorities in technology today as IT organizations the world over race to build future-ready ecosystems.
• Azure AI Search (formerly “Azure Cognitive Search”) is important, and we’ve come a long way since the days when most people knew Cognitive Search as an indexer and provider of traditional end user search across enterprise data. Yes, it still does that, but AI Search is increasingly becoming one of the principal “front doors” through which AI walks in order to use enterprise data. It turns out that a vast index of enterprise data is extraordinarily useful to AI workloads, hence the RAG pattern discussed much earlier. In any case, the implementation of AI Search ought to rank alongside Purview and OneLake in terms of specific data platform services required by an organization seeking to become future ready in the age of AI. Get it. Implement and configure it. Index your consolidated data now and continually into the future.
• The RAG pattern itself is shown in a simplified form, glowing in yellow as a callout.
• We’re also extracting value from our consolidated data in other distribute workloads as well, including integration with outside third parties via API, analytical workloads in Power BI, and some combination of data warehouse, data engineering, and data science workloads using the Synapse technologies integrated with Microsoft Fabric.
High quality data distribution supports our objective for an AI strategy that, “offers immediate value to the organization beyond specific AI-driven workloads because the nature and value of these workloads will remain unclear for some time.”
The diagram above illustrates how sound data readiness - and data distribution, specifically, shown here - supports non-AI workloads as well, including enterprise search, data distribution to third parties, and analytical workloads. The particulars of your data platform architecture may vary, but data distribution is a sound investment within and outside the scope of AI.